简要介绍
论文笔记: Region-based Convolutional Networks for Accurate Object Detection and Segmentation。Ross Girshick 大神后来基于此篇又研究发表了很多论文, 提出了SPP net 和fast RNN。论文里提出用CNN网络来进行目标检测, 不同于图片分类, 目标检测需要在图片内对目标进行定位。这面临着两个问题,一是如何用deep network 定位,二是,如何用现有的少量数据训练一个更泛化的模型。
对于第一个问题,有一种办法是将检测问题转换成回归问题,但这样检测多个目标时需要很复杂的解决办法或者特定假设每张图片里目标的数量。另一种方法是采用滑动窗口,但这样就需要所有的目标有共同的长宽比。 论文里最后采用的recognition using regions方式进行定位,这个方法已经被成功的运用在目标检测和语义分割上。rcnn的步骤主要是三步:
- 每张图片提取大约2000张的类别独立的 region proposal。
- 采用CNN 从每个region proposal进行固定长度的特征提取。
- 用SVM 进行分类,不同类别分布训练一个SVM。
另外,对于数据稀缺问题,可以采用有监督预训练的办法解决。先用大数据例如ILSVRC预训练, 再用domain-specific的数据进行fine-tuning(这个方法也叫迁移学习,transfer learning)。
R-CNN 基本策略
网络的基本流程如下图所示:
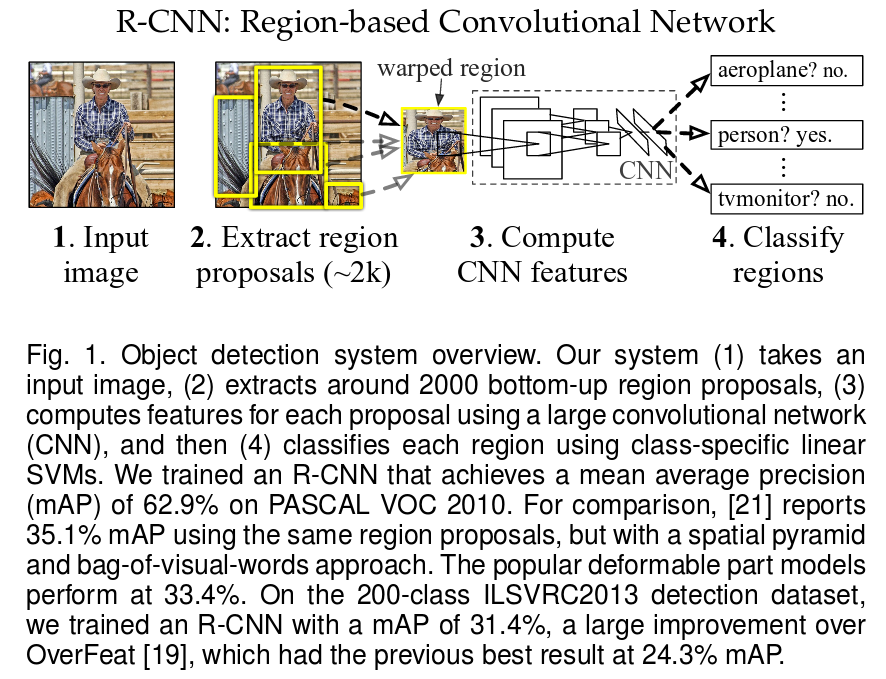
1. region proposal,候选框提取
每张图片要生成大约2000张regionproposals。对于生成类别独立的region proposal,有很多方法,例如:objectness, selective search, category-independent object proposals 以及Ciresan等。论文里采用的是selective search。
2. feature extraction,特征提取
这一步是用一个CNN网络从region proposal中提取一个固定长度的特征向量。特征向量维度是4096维。CNN网络只接受固定大小的输入如227*227,由于候选框的大小和长宽比不一定,所以首先要将不同大小的region proposal wrap成固定大小的。转换方法很多,论文里采用的最简单的方法,如下图:

CNN网络训练提取特征:
训练CNN网络提取region proposal的特征向量,CNN的训练分为两步:
-
supervised pretrain 用 ILSVRC2012 classification的数据预训练 CNN 网络,该数据是一个 1000-way的分类
-
domain-specific fine-tuning 对预训练好了的网络,用wraped 之后的proposals 进行训练。不过如果这个domain数据是N个类,所有CNN网络的最后一层要从1000-way替换成 N+1 way的layer(该layer的参数初始值随机),里面有一个是background。IoU overlap是指两图片重叠面积和相并面积之比。论文里面,设置如果proposal和ground truth 的 IoU overlap >= 0.5时,则认为这个proposal是positive(正样本)的,其余的negative(负样本)。
3. object category cassifier,分类器
每一个类分别训练一个二值SVM分类器,将用CNN网络提取到的那些proposal的特征向量作为svm的输入,得到SVM对于这些proposal的评分结果,对于一张图片的score之后的region proposal,采用非极大值抑制技术找出最终的候选框。
在正负样本的设置中,与fine-tuning 里不同。background为负样本,IoU overlap 阈值<=0.3的也是负样本;只有ground truth是正样本, IoU在0.3到1之间的region忽略。论文发现如果fine tuning时也使用SVM训练时正负样本的定义,准确率下降很多,作者猜测是因为IoU在0.5到1之间的样本被忽略的话,训练数据会少很多,而fine tuning需要一个比较大的数据,可以避免过拟合。但是这些忽略的样本用到SVM训练中的话,会降低定位的精准度。
$emsp;还有一点值得说的是,论文里还提到,对SVM分类之后的region proposal 使用bounding box regression可以减少定位误差,论文里的数据提升了3-4个mAP的百分点。