BWT(Burrows Wheeler Transform)
BWT,数据转换算法,其实也是一种压缩算法,基本思想就是找到字符串的重复部分来进行压缩,还可以用来进行序列比对。BWT会将字符串转换成一个类似的字符串,但是转换后的字符串的相同字符是相邻的,这样,我们就可以对数据进行压缩了。这个算法的解压缩也很方便简单。
BWT原理
BWT编码部分
BWT编码压缩步骤如下:
- 首先对要转换的字符串,添加一个不在字符串里的ASCII码表里最小的字符。如 AGGAGC ——> $AGGAGC,添加了 $ 。
- 对字符串进行依次循环移位,得到一系列的字符串,如果字符串长度为 n, 就可以得到n个字符串,如下面图里的第二列所示。
- 对2中的位移后的一系列的字符串按照ASCII进行排序,如下图的第四列所示,第三列是排序后的字符串的原index位置。
- 取位移后的一系列字符串的首字母出来作为 F 列, 最后一个字母作为 L 列。如下图 F 列 和L 列所示。
- L 列就是最后的编码结果。
| No. | rotated | index | sorted | F | L | LF |
| 0 | AGGAGC$ | 6 | $AGGAGC | $ | C | C->$ |
| 1 | GGAGC$A | 3 | AGC$AGG | A | G | G->A |
| 2 | GAGC$AG | 0 | AGGAGC$ | A | $ | $->A |
| 3 | AGC$AGG | 5 | C$AGGAG | C | G | G->C |
| 4 | GC$AGGA | 2 | GAGC$AG | G | G | G->G |
| 5 | C$AGGAG | 4 | GC$AGGA | G | A | A->G |
| 6 | $AGGAGC | 1 | GGAGC$A | G | A | A->G |
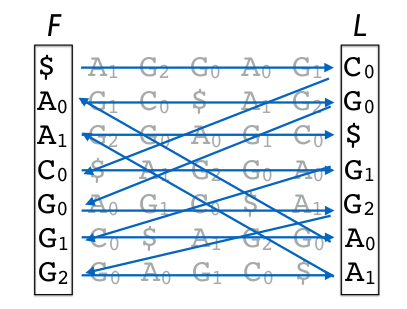
由编码过程,参考上图,其实可以发现BWT编码有三个特性(循环位移决定),
- L 列的第一个元素是源字符串的最后一个元素。
- 循环位移可知,同一行的 F 列和 L 列的元素在源字符串里是相邻的,而且 L 列元素的下一个字符就是 同行里 F 列的元素。
- 同一种字符在 F 列和 L 列里的rank是一样的,比方说, F 列里的第二个 A 和 L 列里的第二个 A 在源字符串里是同一个A。 F 列里的第一个 G 和 L 列里的第一个 G 在源字符串里是同一个G,rank如下图所示。
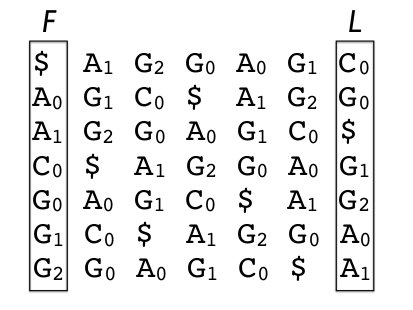
根据以上这三个条件, 我们就可以进行BWT解码,也就是解压缩。
BWT解码部分
BWT解码,已知 L 列, 推源字符串。
- 由 L 列 得到 F 列。因为L 列 和F 列其实都是源串的字符的不同排列方式,但是我们知道 F 列是按照 ASCII码排序的,所以从 L 就可以推出 F 。
- 根据第一个性质,我们可以得到源串的最后一个字符是 L 列的第一个字符,作为当前字符(下面依次往前递推)。
- 依据上一步得到的作为当前字符, 根据第三个性质,我们可以得到同一个字符在 F 列中的位置,作为当前字符。
- 依据 F 列里的当前字符,根据第二个性质,我们可以得到当前字符的上一个字符是同行里的 L 列里的元素,将新增字符作为当前字符,然后跳转到第 3 步。
- 直到所有字符全部推算出来。
整个过程如下图所示: