变分自编码(variant autoencoder,VAE)
VAE 其实是 autoencoder的一个变种 首先介绍一下什么是自编码器(autoencoder):
自编码器(autoencoder)
VAE 基于tensorflow的实现
如下图:
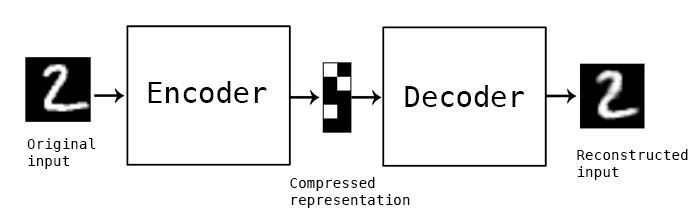
自编码器由两部分组成: encoder 和decoder, encoder对输入数据(x)进行编码得到隐藏层的表达,decoder则对隐藏层的表达进行解码来重构和输入一样节点数大小的输出(y), 模型优化时的目标函数则是x和y之间的重构误差。encoder和decoder可以是 MLP,CNN,RNN等的任意一种结构。
重构误差的目标函数:
重构误差也可以用交叉熵
一般 autoencoder可以用来做数据降维、数据压缩、数据去噪等,传统的深度学习方法也会用autoencoder对CNN网络进行逐层的预训 练。当然,最重要的是,auoencoder还可以用作无监督学习来学习数据的特征表达(其实,autoencoder并不是完全的无监督,更象是一种自监督学习)
变分自编码器(VAE)的基本原理
从上面 autoencoder的原理可以看出, autoencoder是直接去学习的输入数据的隐藏层表达,但VAE则不是如此。
假定认为输入数据的数据集D(显变量)是受到一组隐变量 z 的控制,数据集的分布完全由这组隐变量操控,而这组隐变量之间相互独立而且服从高斯分布。 VAE让 encoder 取学习输入数据的隐变量模型,也就是去学习这组隐变量的高斯概率分布的参数:z_mean,z_log_var,分别表示隐变量高斯分布的均值()和方差()的log值),而隐变量 z 则就可以从这组分布参数中采样得到: , 再通过 decoder 对z隐变量进行解码来重构输入。
但实际中,VAE模型并没有真正的用来采样得到z变量, 因为这样采样之后,没有办法对进行求导,也就没有办法用梯度下降算法对目标函数进行优化。VAE采用一个叫reparemerization的trick:先采样一个标准高斯分布(正态分布): , 然后,这样得到的z就是服从,同时也可以正常的对进行求导了。
模型框架如下所示:

从图可以看出, VAE主要分成以下三大模块:encoder,sample,decoder
1. encoder:
学习隐变量的概率分布参数
伪码如下:
def encoder(self, input, n_hidden, m):
n_in = int(input.get_shape()[1])
shape=[n_in, n_hidden]
w = tf.Variable(tf.truncated_normal( shape, stddev=0.001))
b = tf.Variable(tf.zeros([hidden]))
hidden= tf.nn.relu(tf.matmul(input,w)+b)
shape = [n_hidden, m]
w_var = tf.Variable(tf.truncated_normal( shape, stddev = 0.001))
b_var = tf.Variable(tf.zeros([m]))
w_mean = tf.Variable(tf.truncated_normal( shape, stddev=0.001))
b_mean = tf.Variable(tf.zeros([m]))
z_var = tf.matmul(hidden,w_var) + b_var
z_mean = tf.matmul(hidden,w_mean) + b_mean
return (z_mean, z_var)
2. sample: 采样一个标准高斯分布,并通过encoder学习到的参数,生成 z
def sample_z(self, z_mean, z_var, std=1.0):
epsilon = tf.random_normal(z_var.get_shape(),mean=0, stddev=std)
z = tf.mul(tf.exp(0.5*z_var) , epsilon) + z_mean
return z
3. decoder: 通过z来重构输入x得到y,
def decoder(self, input, n_hidden, n):
n_in = int(input.get_shape()[1])
shape=[n_in, n_hidden]
w1 = tf.Variable(tf.truncated_normal( shape, stddev=0.001 ))
b1 = tf.Variable(tf.zeros([n_hidden]))
hidden= tf.nn.relu(tf.matmul(input,w1)+b1)
shape=[n_hidden, n]
w2 = tf.Variable(tf.truncated_normal( shape, stddev=0.001 ))
b2 = tf.Variable(tf.zeros([n]))
y= tf.nn.sigmoid(tf.matmul(hidden,w)2+b2)
return y
关于目标函数,目标函数由两部分组成: x ,y的重构函数以及 z 变量的 KL 散度;
重构函数:
KL 散度:
总的目标函数:
def loss(self, x, y, z_mean,z_var):
entropy = tf.nn.sigmoid_cross_entropy_with_logits(x,y)
loss = tf.reduce_sum(entropy,1)
kl_loss = -0.5*tf.reduce_sum(1+z_var - tf.square(z_mean)-tf.exp(z_var) ,1)
all_loss = tf.reduce_mean(loss + kl_loss)
return all_loss
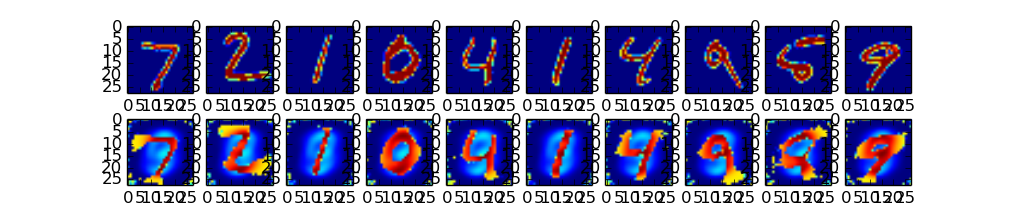
实验结果:
第一行是手写体的原数据图
第二行是VAE重构的结果: