RNN ,recurrent neural network
最近忙着看了关于RNN的几篇论文,主要参考了论文Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling然后基于RNN作了一个音乐生成的项目music_rnn, 想着将RNN有关的知识点记录下来,方便以后自己回顾,也供大家参考讨论。 因此整理一下以下知识点。
- RNN网络介绍
- LSTM网络和GRU网络的理解
- RNN-RBM网络的理解(将在下一篇博客中介绍)
虽然不及CNN火爆热捧,感觉RNN网络应用也十分强大,在NLP,机器翻译,语音识别,音乐创作方面都有着很大的潜力和优势。 相较于其他网络主要用于分类问题,RNN网络主要用于序列预测或生成, 由于网络带有记忆性,可以充分学习到数据里的上下文信息,因此在自然语言处理等方面有着其他网络所不及的效果。例如,给一个单词序列,可以预测下一个单词。由于一条语句里面的各个单词不是独立存在的,当你需要的下一个单词是什么的时候,一般是通过这个单词前面的一些单词来进行预测。而事实上,预测一个单词不仅与前面的单词序列相关,也与句子后面的单词序列相关,俗称为上下文信息,其实可以通过一个双向的RNN网络来进行预测,就可以考虑到前后的上下文信息了,双向的RNN网络其实也就是两个RNN网络的叠加。不过,这篇博客暂时不会介绍双向RNN。
现在有人开始研究将RNN 和CNN相结合,进行图像描述生成(generating image descriptions)研究。CNN模块部分捕获图像的特征信息,RNN模块部分则负责依据CNN捕获的特征信息来生成图像描述文字。
1. RNN 简单介绍
1.1 网络结构
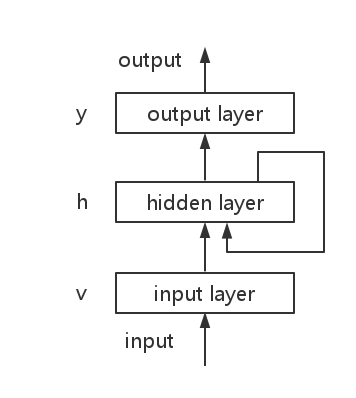
RNN 可以用来处理具有记忆性或者时序性的数据,例如每个时刻逐次输入语句的单词。而网络当前时刻的输出不仅与当前时刻的输入有关,还依赖于上一时刻的输出,因此就会受到之前输入的影响。最基本的RNN分为elman网络,和jordan网络。elman的时序依赖性是隐藏层 h 层,而jordan网络的依赖性则是输出层。
elman网络结构如下图所示:
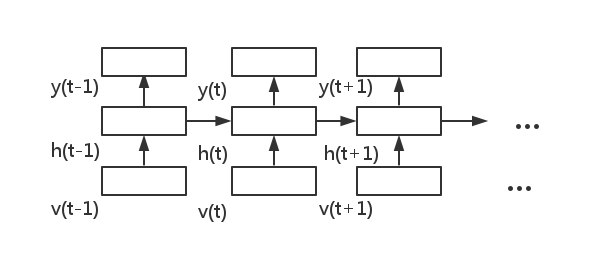
网络沿时序展开,则如下所示:
1.2. forward, 前向推导
elman网络前向计算:
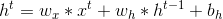
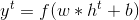
jordan网络前向计算:
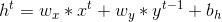
其中 f 表示激励函数, 例如 sigmoid,tanh,ReLU 或者 softmax 函数 ,x 表示输入,h 表示隐藏层状态, y 为经过激励函数之后的输出,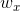 ,
,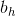 ,w, b 则是网络的权重或偏置参数。从前向公式可以看出, elman网络和jordan网络的差别就在于,前者计算当前时刻隐藏层时依赖于上一时刻的隐藏层, 后者则是依赖于上一时刻激励函数之后的输出
,w, b 则是网络的权重或偏置参数。从前向公式可以看出, elman网络和jordan网络的差别就在于,前者计算当前时刻隐藏层时依赖于上一时刻的隐藏层, 后者则是依赖于上一时刻激励函数之后的输出
RNN网络梯度下降方法不再采用随机梯度下降(SGD), 而采用RMSprop。
1.3 目标函数
可以采用常用的 categorical_crossentropy
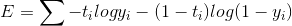
2. LSTM 和 GRU
最普通的RNN有一个很严重的问题,即gradients倾向于vanish或者explode, 大多数情况下会vanish, 也就是梯度消失, 因此 RNN 训练时很难捕获到长期的记忆long-term dependencies。为了解决这一问题,Hochreiter and Schmidhuber 提出了long short-term memory unit(LSTM, 长短期记忆单元), 后来又有人提出了 gated recurrent unit(GRU),相比于 RNN, 这两种结构在捕获长期记忆方面效果显著, 并被广泛用于NLP, 语音识别等。
这两种单元的结构分别如下图所示:
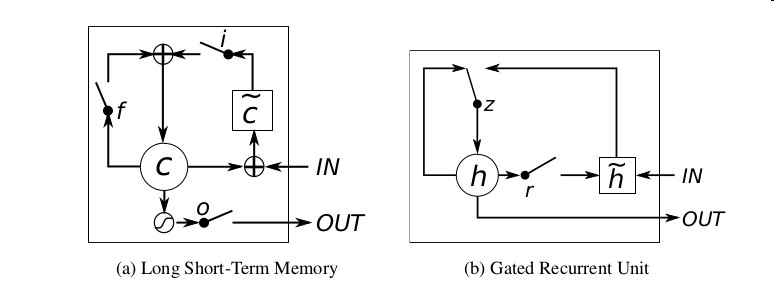
以上左图(a)为LSTM, 右图(b)为GRU
- (a) : i, f, o 分别是输入门,记忆门以及输出门,c 和
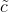 则分别是记忆单元和新记忆单元
则分别是记忆单元和新记忆单元 - (b) : r 是重置门, z 是更新门, h 和
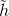 则分别是隐藏层和候选隐藏层, 输出是隐藏层
则分别是隐藏层和候选隐藏层, 输出是隐藏层
2.1 LSTM
相较于RNN, LSTM是在维护一个记忆单元 c(被称为cell),如图中所见,cell保存上一时刻的隐藏层状态,并通过两个门控单元i 和 f ,结合上一隐藏层状态,当前输入,当前记忆单元来对记忆单元进行更新,并计算输出。
LSTM网络的输出计算式是
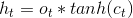
而上式中记忆单元的维护是通过部分忘记现有的记忆,添加部分新的记忆 来完成的
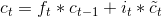
其中, 则是由下式计算所得
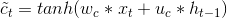
三个门控单元则分别由下式计算
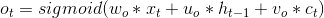
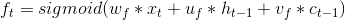
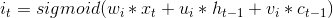
2.2 GRU
GRU网络与LSTM网络非常相似,也是普通RNN的改良版本,但在门控单元控制上有所改变
GRU的输出就是 h ,h的计算式如下:
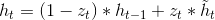
候选隐藏层的更新与基本RNN中的计算方法类似,由下式计算,其中dot表示点乘:
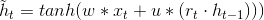
两个门控单元的更新与LSTM中门控单元的更新类似:
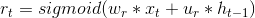
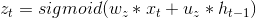
2.3 总结分析
LSTM和GRU都可以有效的处理长短期记忆问题,至于哪种更好,不同的数据集会有不同的表现。结构上两者很相似,GRU比LSTM要简单,两者相比, 主要的不同有两点
- LSTM中记忆单元的更新由 f 和 i 两个独立的门控单元控制,新记忆单元则没有门控制;而GRU计算隐藏层时由一个门控单元z同时控制过去记忆的留存和新隐藏层是否流入,新的(候选)隐藏层则有门控单元控制
- LSTM 有独立的记忆单元, 从记忆单元 c 到输出经过了激励函数以及输入控制门; GRU的隐藏层即为输出,没有门控单元
3. 参考及推荐
- deeplearning.net tutorial 介绍 RNN, RNN做词嵌入(word embeddings)
-
论文
- how toconstruct deep RNN
- On the difficulty of training recurrent neural networks
- Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, bengio大牛实验室做了一系列的将RNN用于机器翻译的论文