很多人对神经网络的前向过程比较清楚,对反向传播算法则比较模糊。因此想在这里简单的写一下反向传播过程中权重更新的推导过程。反向推导主要就是一个对权重值求导的过程, 求导时利用了链式法则。这里简单的介绍一下全连接的神经网络的反向传播的推导,RBM, autoencoder, deepAutoEncoder和 RNN 的推导与这种全连接的反向求导推导类似,CNN网络的则要不一样些,但其实也还是利用的链式求导法则。
神经网络的一个训练过程,可以看作是优化权重来优化代价函数的过程。多层神经网络的参数优化问题其实是一个高阶的非凸优化的问题,普通的优化算法很容易陷入较差的局部最优解。神经网络大多采用随机梯度下降算法,可以获得一个较好的局部最优解,(pre-trainging 可以获得一个较好的接近局部最优解的出世迭代点)。代价函数可以采用交叉熵代价函数、平方损失函数等,这里推导采用交叉熵的代价函数。
logistic 求导
先介绍以下logistic模型的求导过程,这是一个单层的神经网络,多层的神经网络的求导其实和这个一样,只是一直往前递推。
FeedForward,前向传播过程
下面三个式子就是Logistic的前向传播过程, 其中 E 表示的就是代价函数
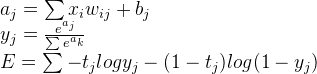
上式中,a表示全链接结果,a到y的计算是softmax函数,最后 E 则是代价函数的计算方法。softmax的输出被归一化到0-1之间,所有值相加是1,可以认为是预测结果的概率值
BackPropagate,反向传播
反向传播过程是计算权重w,b的梯度,也就是代价函数E对参数的偏导值。
根据链式求导法则一步步往前求导,过程如下所示:
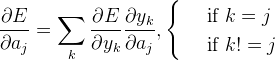
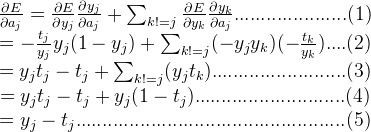
最后,再求w,b的偏导就是:
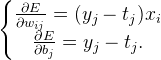
求出偏导值后,用权重参数减去其对应的梯度,就是更新之后的权重参数:
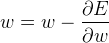
MLP 求导
MLP其实就是一个多层的全连接网络,基于上面的logistic的反向过程,我们可以用同样的方法来推导MLP的反向传播过程。
FeedForward, 前向传播过程
下面是一个两层全连接,一层sotfmax连接网络的前向传播过程,其他层次数的MLP类似:
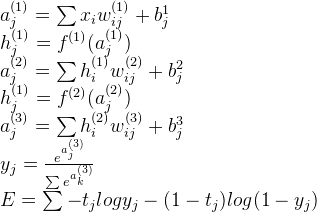
其中f()表示激励函数,可以是sigmoid,tanh,ReLU等函数
Backpropagate, 反向传播
我们首先假设 E 对第 l 层的 a 的偏导值如下:
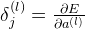
由上面的logistic的推导过程,我们可以得到MLP的最后一个softmax层的推导如下:
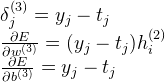
由上式,我们继续往后推导求第 l 层的 a 的偏导值:
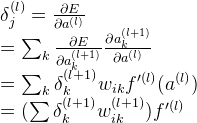
则第 l 层的w,b的偏导值如下:
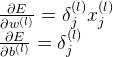
利用链式求导法则,一直往后推导,就可以计算得到第一层的权重参数的偏导值,最后,反向推导过程完成。