Batch Normalization(BN算法)
BN算法是论文Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift提出的算法,算法看起来很简单,可以当作一个单独的层次加入到网络中,效果非常显著啊。
背景
在深度网络的训练过程中,整个网络的输入数据我们一开始就会进行归一化处理,但由于前面网络的参数微小变化,会随着层次前向逐步累积放大,会使后面层次的网络的输入的分布改变,这就是Internal covariate shift ,这种情况下就需要我们有较好的权重初始值和降低学习率,从而导致学习较慢。
然而,如果每一层的输入数据都有固定的分布(包括训练数据和测试数据),会对训练比较有利,模型也会有较好的泛化能力。于是,大家就考虑到对每一层的输入进行归一化处理来固定分布,Batch Normalization就是解决了这个问题(减少Internal covariate shift)。
意义
BN算法很厉害,深度网络训练时参数初始化很重要,各种超参(学习率、正则化系数、权重衰减系数等)和trick的选择也很让人很麻烦,BN算法就可以帮我们省却这些麻烦。
- 可以选择较大的学习率。在有BN算法的模型中,可以一开始就选较大的学习律而不用担心gradient vanish,也就不需要逐个尝试学习率大小选择最合适的。
- 权重初始化可以相对随意些。BN减少了gradient flow 对权重初始值的依赖。
- 去掉Dropout。BN算法可以达到dropout的目标,因此可以去掉Dropout而不产生过拟合。
- 去掉L2正则化。BN模型中,权重的L2 loss会减少5倍。
- 加速学习率的衰减。通常训练时,学习率会以指数形式衰减,在BN模型中,衰减速度可以加速6倍左右。
- 可以把数据彻底打乱。避免某个样本总是被batch选中,可以提高准确率1% ?
- 减少photometric distoritions(不懂这是个啥)。
- 加速训练过程。以更少的training steps可以达到相同的准确率。
Normalization 和Batch Normalization
众所周知的是,如果神经网络的每一层的输入都是白化数据(例如线性变换成0均值,1方差,feature去相关的数据)的话,网络训练时收敛更快。但是如果完全白化所有层的输入,代价太大。在讲BN之前,我们先来看一下一个简单的归一化处理操作,可以将数据近似白化处理,也就是0均值,1方差,但是feature之间相关。
1. 近似白化处理
就是下面的这个公式,简单粗暴,大家肯定在其他地方的都用过,对每一个神经元进行归一化处理,就是简单的将数据变成0均值,1方差:
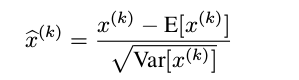
但是,其实简单的归一化处理,效果并不好,它会改变前面这一层的所学习的特征的表达。比方说,有一个sigmoid曲线分布的输入,如果进行简单的归一化,原本分布在非线性区域(s曲线两端)的就被强制归一化到线性区域(s曲线中间)。想要解决这个问题,归一化处理必须是一个恒等的变换,特征表达不能改变,由此,就产生了BN算法。
2. BN算法
为了保证恒等变换,BN算法在上面的归一化处理上加入了非常重要的一步,新引入了两个可以学习的参数,对归一化之后的数据进行下面的重构处理:
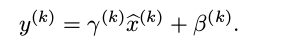
其中,
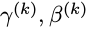 是可以学习更新的参数,每一个神经元一对这样的参数。可以发现,BN算法可以当成一层网络加入到神经网络模型中,就和全链接层,激励层,卷积层,池化层等一样的。该层有两个可学习参数。而且当有:
是可以学习更新的参数,每一个神经元一对这样的参数。可以发现,BN算法可以当成一层网络加入到神经网络模型中,就和全链接层,激励层,卷积层,池化层等一样的。该层有两个可学习参数。而且当有:
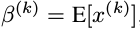
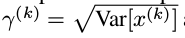
该BN层可以恢复该层的输入层所学习到的特征表达。在训练过程中,两个参数不断更新学习,这样就可以恢复原始网络所学习的特征分布。
BN网络
首先写一下BN算法的前向推导:

理论上,网络训练是在整个数据集上,归一化时,应该用整个数据集来计算均值方差进行归一化,但在SGD优化算法中,这样并不是一个可行的办法。退而求其次,论文里提出用mini-batch里面的数据来估计均值和方差。
1. BN网络
在全链接网络中,BN层通常在全链接层之后,激励层之前(激励层:sigmoid,tanh,ReLU等)。例如,本来全链接网络的forward如下所示:
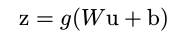
在加入BN层之后:
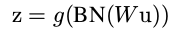
不过上面这个式子里的偏置参数 b 其实可以去掉,因为 b 会被均值归一化,重构时也有偏置函数。
2. CNN网络中的BN
CNN 中的BN层也是在卷积层之后,在激励层之前。不过有点不同,全链接网络当中,均值化是对每一个神经元进行均值化,但是如果CNN网络也对每一个神经元均值化,这样会产生非常多的
参数对。比方说,如果某一层,有64个feature map,每一个map大小是60**60,如果每一个神经元都归一化,那么就会有64*60 *60个参数对,这违背了CNN权值共享的精髓思想。考虑到权值共享,作者提出对整个feature map进行整体的归一化,把一个feature map当作一个神经元,这样就只有 64 对参数了。