强化学习,目的就是求解MDP(马尔科负决策过程),而MDP的求解有三种情况:
- 动态规划求解法:求解一个已知环境完整知识的MDP。有两种方法:
- 策略迭代
- 值迭代
- Model free prediction:对于一个环境知识不完整的MDP, 估计状态值函数。有两种方法:
- 蒙特卡罗法: MC
- 时间差分学习法: TD
- Model free control: 对于一个环境知识不完整的MDP, 优化状态值函数。
第三节,本篇博客就是讲的动态规划求解法,还有两种接下来的两节博客会讲到。
1. 贝尔曼方程,Bellman Equation
这里回顾一下上一节讲MDP时讲到的 Bellman equation
贝尔曼期望方程: Bellman Exception Equation
上一节提到了对于给定策略,如何计算状态值函数Vπ和动作值函数qπ,方程式如下:
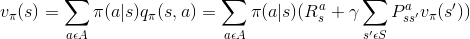
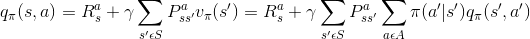
这就是bellman exception equation, 从式子可以看出来,当前状态的值函数Vπ和下一状态的值函数相关。
贝尔曼优化方程:Bellman Optimal Equation
关于寻找最优策略,是指时所有状态值函数最大的策略,而关于最优策略下的优化状态值函数和优化动作值函数,是满足bellman optimal equation方程的,也就是如下式两个方程:
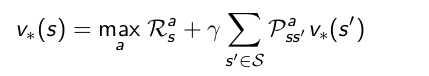
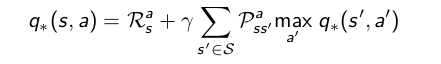
有了贝尔曼期望方程和贝尔曼优化方程,我们就可以利用动态规划求解法求解MDP的最优策略了,求解方法有策略迭代和值迭代两种。
2. 策略迭代: Policy Iteration
在讲策略迭代之前,先讲以下这个方法用到的两个基本步骤:策略估计和策略改进。
2.1 策略估计:Policy evaluation
策略估计:给定一个策略π,计算该策略下的所有状态值函数Vπ(S),可以通过迭代贝尔曼期望方程求解。
贝尔曼方程告诉了我们对于确定的策略,如何求状态值函数,但是一般某个策略下,某个状态π(S)对应的动作a可能有很多种,一般采用多次迭代的方法更新状态值函数:
V1——>V2——>…——>Vπ
- 首先初始化所有状态值函数V(s)为0
- 进行迭代,也就是重复步骤 3直至收敛。对于每一次迭代 k+1,进行步骤 3 :
- 遍历状态,对每一个状态 s in S,都进行以下操作:
- 采用下面式子对状态 s 的状态值函数进行更新。
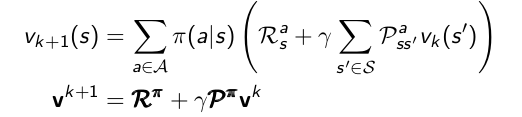
- 采用下面式子对状态 s 的状态值函数进行更新。
- 最后收敛至 Vπ,就是该策略的状态值函数。
最后,举个栗子,关于策略估计,假设一个4*4格子,左上角和右下角是终止状态点,非终止状态14个,明日歌状态可以采取的动作是移到相邻的格子(碰壁则留在原状态),上下左右移动概率相等,都是0.25,转到终止态回报为0,其他任意转移的reward都是 -1,γ是1。
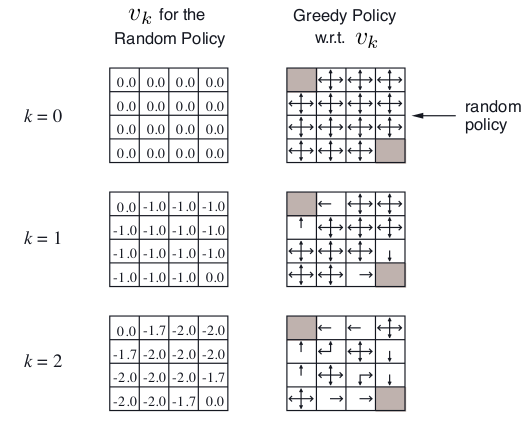
在k=0,初始状态是随机策略,V(s)全部随机为0.
k=1, 第一行第二列, v = 0.25*(-1+0)+ 0.25*(-1+0)+ 0.25*(-1+0)+ 0.25*(-1+0)= -1.0 ;
k=2, 第一行第二列, v = 0.25*(-1+0)+ 0.25*(-1-1)+ 0.25*(-1-1)+ 0.25*(-1-1)= -1.75 = -1.7;
k=2,第一行第三列, v = 0.25*(-1-1)+ 0.25*(-1-1)+ 0.25*(-1-1)+ 0.25*(-1-1)= -2.0;
2.2 策略改进:Policy improvement
策略改进:是为了寻找一个更好的策略,对于一个策略,我们到底能不能找到更好的策略呢。如果对于策略π,对某个状态,采用的动作a0得到状态值函数,如果我们采取其他动作,会不会更好。怎么判断动作的好坏,我们就可以通过计算动作值函数来判断了,通过选取动作值函数最大的动作来改进策略获得新策略:
对于一个确定的策略,对每个状态,遍历这个状态的所有可能动作,采用贪心算法来获得新的优化的策略,步骤如下:
- 遍历状态 s, 对每个状态 s in S,采用下面式子进行更新。
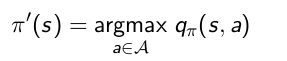
2.3 策略迭代
策略迭代的过程,其实就是策略估计和策略改进的组合,比如先随机给定一个策略,利用策略估计计算它的状态值函数,然后利用策略改进获得新策略,然后重复计算策略估计和策略改进,直至收敛。
- 随机初始化一个策略
- 重复步骤 3,4,直至收敛
- 策略估计:
多次迭代,对每个状态值函数进行更新直至收敛得到该策略的状态值函数。 - 策略改进:
对每个状态进行改进,找动作值函数最大的动作来改进策略获得新策略。 - 最后策略收敛稳定时,返回的值函数和策略就是想要的结果。
整个过程图解如下:
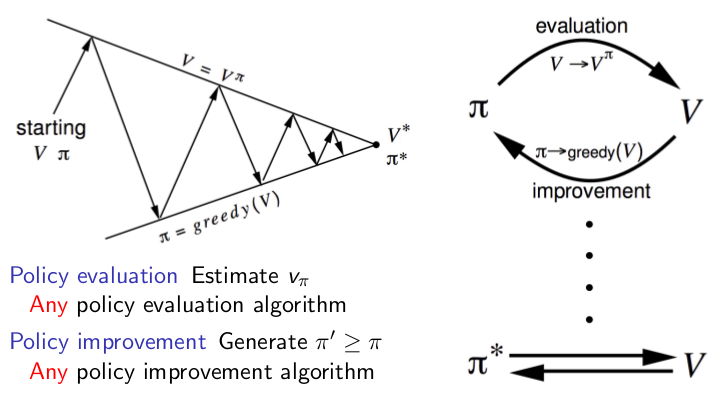
看图,策略迭代的过程就是根据策略迭代计算这个策略下每个状态的值函数,然后根据状态值函数来,利用贪心算法改进策略,不断的重复这两个步骤,最后收敛,所得到的就是优化策略。
3. 值迭代
可以发现,其实策略迭代的方法计算量很大,在策略估计的过程中,每一个状态都要扫描很多次,这样代价太大。但是值迭代,每次迭代时,每个状态只需要扫描一次。
V1——>V2——>…——>V*
- 首先初始化所有状态值函数V(s)为0
- 迭代操作,即重复步骤 3直至收敛。对于每一次迭代 k+1 :
- 对每一个状态 s in S,都进行以下操作:
- 采用下面式子对状态 s 的状态值函数进行更新。

- 采用下面式子对状态 s 的状态值函数进行更新。
- 最后收敛的输出策略就是所求最优策略 π*。
一般来说,迭代次数很多才会收敛,实际计算的时候,可以根据精度需求来设置收敛阈值。
举个栗子,计算最短路径, 只有终止态回报为0, 其他都是-1,γ=1,如下图所示:
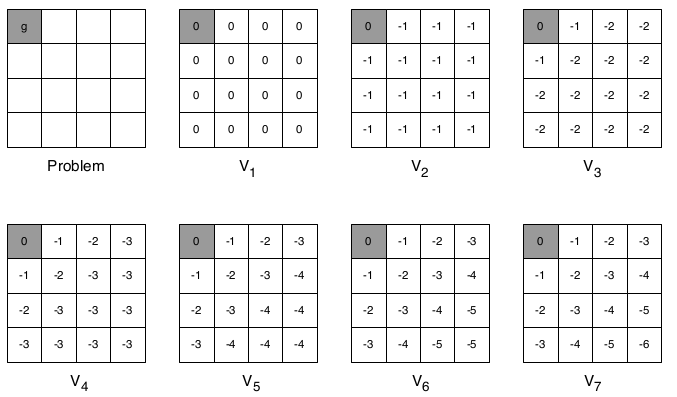
第一次迭代,初始化最大V值都是 V = 0;
第二次迭代,第一行第二列,下一状态不管往哪走,最大V值都是 V=-1 + 1*(0) = -1;
第三次迭代,第一行第二列, 向左走到终止态时,当前状态V最大, V = -1 + 1*(0) = -1;
第三次迭代,第一行第三列, 不管往哪走当前状态V一样, V = -1 + 1*(-1) = -2;
第四次迭代,第一行第三列, 往左走,当前状态V最大, V = -1 + 1*(-1) = -2;
第四次迭代,第二行第二列, 往上或者左走,当前状态V最大, V = -1 + 1*(-1) = -2;
4. 总结
通过策略迭代和值迭代都可以求出最优策略。下面有个表格总结以下完整环境知识下的MDP各种问题的求解:
