Welcome to CJW's Blog!
关于deeplearning, 关于 machine learning-
各种机器学习方法简单介绍和比较
(基本上都是从各个博客总结而来)
各种机器学习算法比较
判别方法:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。典型的判别模型包括k近邻,感知级,决策树,支持向量机等。
生成方法:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)
- 偏差:描述的是预测值(估计值)的期望E’与真实值Y之间的差距。偏差越大,越偏离真实数据。
- 方差:描述的是预测值P的变化范围,离散程度,是预测值的方差,也就是离其期望值E的距离。方差越大,数据的分布越分散。
对于小训练集,高偏差/低方差的分类器(例如,朴素贝叶斯NB)要比低偏差/高方差大分类的优势大(例如,KNN),因为后者会发生过拟合(overfiting)。然而,随着你训练集的增长,模型对于原数据的预测能力就越好,偏差就会降低,此时低偏差/高方差的分类器就会渐渐的表现其优势(因为它们有较低的渐近误差),而高偏差分类器这时已经不足以提供准确的模型了。当然,你也可以认为这是生成模型(如NB)与判别模型(如KNN)的一个区别
在统计学习框架下,大家刻画模型复杂度的时候,有这么个观点,认为Error = Bias + Variance。这里的Error大概可以理解为模型的预测错误率,是有两部分组成的,一部分是由于模型太简单而带来的估计不准确的部分(Bias),另一部分是由于模型太复杂而带来的更大的变化空间和不确定性(Variance)。模型越复杂,方差越大,偏差越小
-
VAE变分自编码器
变分自编码(variant autoencoder,VAE)
VAE 其实是 autoencoder的一个变种 首先介绍一下什么是自编码器(autoencoder):
自编码器(autoencoder)
VAE 基于tensorflow的实现
如下图: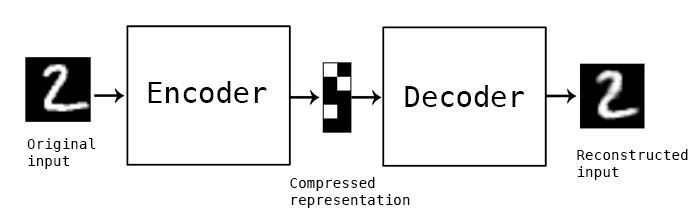
自编码器由两部分组成: encoder 和decoder, encoder对输入数据(x)进行编码得到隐藏层的表达,decoder则对隐藏层的表达进行解码来重构和输入一样节点数大小的输出(y), 模型优化时的目标函数则是x和y之间的重构误差。encoder和decoder可以是 MLP,CNN,RNN等的任意一种结构。
重构误差的目标函数: 重构误差也可以用交叉熵一般 autoencoder可以用来做数据降维、数据压缩、数据去噪等,传统的深度学习方法也会用autoencoder对CNN网络进行逐层的预训 练。当然,最重要的是,auoencoder还可以用作无监督学习来学习数据的特征表达(其实,autoencoder并不是完全的无监督,更象是一种自监督学习)
变分自编码器(VAE)的基本原理
从上面 autoencoder的原理可以看出, autoencoder是直接去学习的输入数据的隐藏层表达,但VAE则不是如此。 假定认为输入数据的数据集D(显变量)是受到一组隐变量 z 的控制,数据集的分布完全由这组隐变量操控,而这组隐变量之间相互独立而且服从高斯分布。 VAE让 encoder 取学习输入数据的隐变量模型,也就是去学习这组隐变量的高斯概率分布的参数:z_mean,z_log_var,分别表示隐变量高斯分布的均值()和方差()的log值),而隐变量 z 则就可以从这组分布参数中采样得到: , 再通过 decoder 对z隐变量进行解码来重构输入。
但实际中,VAE模型并没有真正的用来采样得到z变量, 因为这样采样之后,没有办法对进行求导,也就没有办法用梯度下降算法对目标函数进行优化。VAE采用一个叫reparemerization的trick:先采样一个标准高斯分布(正态分布): , 然后,这样得到的z就是服从,同时也可以正常的对进行求导了。模型框架如下所示:

从图可以看出, VAE主要分成以下三大模块:encoder,sample,decoder
1. encoder: 学习隐变量的概率分布参数
伪码如下:def encoder(self, input, n_hidden, m): n_in = int(input.get_shape()[1]) shape=[n_in, n_hidden] w = tf.Variable(tf.truncated_normal( shape, stddev=0.001)) b = tf.Variable(tf.zeros([hidden])) hidden= tf.nn.relu(tf.matmul(input,w)+b) shape = [n_hidden, m] w_var = tf.Variable(tf.truncated_normal( shape, stddev = 0.001)) b_var = tf.Variable(tf.zeros([m])) w_mean = tf.Variable(tf.truncated_normal( shape, stddev=0.001)) b_mean = tf.Variable(tf.zeros([m])) z_var = tf.matmul(hidden,w_var) + b_var z_mean = tf.matmul(hidden,w_mean) + b_mean return (z_mean, z_var)2. sample: 采样一个标准高斯分布,并通过encoder学习到的参数,生成 z
def sample_z(self, z_mean, z_var, std=1.0): epsilon = tf.random_normal(z_var.get_shape(),mean=0, stddev=std) z = tf.mul(tf.exp(0.5*z_var) , epsilon) + z_mean return z3. decoder: 通过z来重构输入x得到y,
def decoder(self, input, n_hidden, n): n_in = int(input.get_shape()[1]) shape=[n_in, n_hidden] w1 = tf.Variable(tf.truncated_normal( shape, stddev=0.001 )) b1 = tf.Variable(tf.zeros([n_hidden])) hidden= tf.nn.relu(tf.matmul(input,w1)+b1) shape=[n_hidden, n] w2 = tf.Variable(tf.truncated_normal( shape, stddev=0.001 )) b2 = tf.Variable(tf.zeros([n])) y= tf.nn.sigmoid(tf.matmul(hidden,w)2+b2) return y关于目标函数,目标函数由两部分组成: x ,y的重构函数以及 z 变量的 KL 散度;
重构函数:
KL 散度:
总的目标函数:
def loss(self, x, y, z_mean,z_var): entropy = tf.nn.sigmoid_cross_entropy_with_logits(x,y) loss = tf.reduce_sum(entropy,1) kl_loss = -0.5*tf.reduce_sum(1+z_var - tf.square(z_mean)-tf.exp(z_var) ,1) all_loss = tf.reduce_mean(loss + kl_loss) return all_loss实验结果:
第一行是手写体的原数据图
第二行是VAE重构的结果: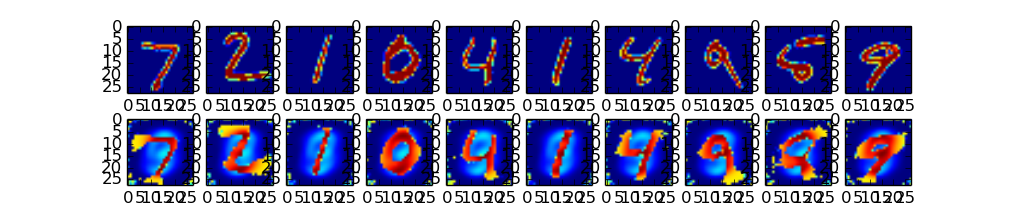
-
汇编之Data Movement Instructions
2017-01-021. 汇编的数据类型
在汇编的指令里,最常用的就是copy data 的指令,可以将汇编的所有指令汇总成 instruction classes, 每个class里的所有指令做的数据类型不同的同一种操作。比如 mov ,基于不同的数据类型,有不同的指令。首先,关于64位系统里的汇编的数据类型与C++ 对照如下:

2. data movement instruction
将数据从一个location(源地址) copy到另一个 location(目的地址),称之为 move,
- 源地址, 可以是 immediate(常数),register,memory
- 目的地址, 可以是 register, memory
不过 ,在 x86-64的系统里禁止从 memory到memory的mov。
2.1 MOV
基于不同的数据类型, MOV 指令集有以下几个指令:

关于以上的mov指令,有一个需要注意的是 movl指令, 当目的地址是 register时,movl会register的高位的4个byte置 0 。(源数据 4个byte, register是 8个byte)。不过,对于movb,movw,即使目的地址是register,并不会将高位置 0 ,而是保留原值。举个小例子如下:

上图里的数据是16进制表示的,可以发现 ,对于 1-3行的mov指令,高位的字节是保留原字节的,但是第 4 行的 movl指令将高位的4 个byte置 0 了。 对于MOV指令集 ,除了以上提到的,还有两大类,MOVZ和MOVS
- MOVZ, 补零扩展的 MOV。
- MOVS, 符号位扩展的 MOV。
2.2 MOVZ
关于 MOVZ的指令集如下所示,

可以发现,这个指令集里没有从 double word 到 quad word 的mov,逻辑上可以写成movzlq指令,其实是因为这个指令其实和movl一样,都是高位 4 byte为0.
2.3 MOVS
MOVS 是指符号位扩展,也就是将空缺的高位补成符号位。关于 MOVS的指令集如下所示,

和MOVZ相比,MOVS里就有 movslq指令。另外,MOVS里还有一个指令 cltq,其实这个指令并不是一个真正的mov指令, 而是对 32位的寄存器 %eax符号位拓展成 64位的寄存器 %rax,所以这个指令的源地址和目的地址分别固定为 %eax 和 %rax。这个指令的效果和 $ 相同
2.4 push and pop stack data
程序运行时,会有一个 stack内存用来存储数据,这个栈是向下增长的,也就是说栈顶是低地址。程序对于栈入栈出栈的操作指令也是一种 MOV 指令:
- pushq S,将数据 S 压入栈顶。
- popq D,从栈顶删除数据并将该数据写入 D。

%rsp 是stack pointer, 指向栈顶。
-
程序编译,链接
简介
一般我们写的编程语言 eg. C++ ,C 等都是高级编程语言,并不能倍机器直接认识,高级语言需要先转换成低级的机器语言指令,才能被机器执行。将这些指令打包到一个 executable object program里面,这个executable object program 就是我们常说的可执行文件 executable object file。
关于 GNU , GNU 是一种编译工具,支持的语言有 C,C++ ,java ,fortran,pascal object-C,Ada等。编译过程
以helloword为例子, hello.c:
#include <stdio.h> int main() { printf( 11 hello, world\n 11 ) ; return O; }在linux系统上,把一个源文件(hello.c) 转换成 可执行文件(hello)需要四个步骤:
- 预处理 ,preprocessing
预处理是处理 ‘#’开头的代码行,例如 #include,预处理器会读取系统头文件 stdio.h里面的全部文件 并插入到hello.c里,这一步生成的文件还是文本的 program,后缀 .i 。
gcc -E hello.c -o test.i- 编译 , compilation
编译是指将文本的程序代码(hello.i)编译成汇编语言的程序代码(hello.s)。hello.s也是text file.汇编语言以一种人能理解的方式描述了机器语言指令。对于不同的编译器和不同的语言, 汇编语言提供了一种通用的语言模式。
gcc -S hello.i -o test.smain: sub'q $8, %rsp movl $.LCO, %edi call puts movl $0, %eax addq $8, %rsp ret- 汇编, assembly
汇编将汇编语言(hello.s)转换成机器语言指令,并打包成可重定位的目标代码(relocatable object program),存储成二进制的目标文件(hello.o)
gcc -c hello.s -o test.o- 链接, linking
链接是将 程序的目标文件和其他所需的目标文件链接起来生成最后的可执行文件。
关于其他所需的目标文件, 可能是调用的自己项目里的其他目标文件,也可能是调用的第三方库文件,以及系统库文件。例如helloword里用到的printf函数,其实现方法是在一个printf.o 的目标文件里, 链接需要将 hello.o 和 printf.o 链接起来生成 可执行文件(hello) 。
gcc hello.o -o hello静态库(.a) 和 动态库(.so)
1. 静态库:
- 在程序编译的时加载到程序里,所以程序运行时删掉.a文件也可以运行。
-
编译时需要指定库文件路径(通过-L参数传递),也要指定库名(-l),
LDFLAGS=-L/usr/lib -L/path/to/your/lib LIBS = -lpthread -liconv
eg,Makefile里通常用LDFLAGS指定库路径,LIBS指定库名:关于编译过程,假设libhello.a和main.c在一个目录下:
gcc -c main.c gcc -o hello main.o libhello.a //gcc -o hello main.o -L. -lhello //可替代上句 //gcc -o hello main.c -L. -lhello //可替代一二句编译时,非系统库不能放在main文件之前,否则会报错未定义。
2. 动态库
- 在程序运行时才加载到程序中,所以运行时也需要库文件的存在
- 编译时,和静态库一样,需要指定动态库库路径和库名
静态库函数改变后,调用静态库的源码也需要重新编译 动态库函数改变后,调用动态库的源码不需要重新编译
- 预处理 ,preprocessing
-
convolution和deconvolution
卷积
首先简单的介绍一下卷积的定义,如下图,f 和 g 卷积, 相当于把 g 翻转之后沿着 x 轴滑动来累计两函数的积分值。如下图所示:

图像卷积(convolution)的三种形式
大家看CNN(卷积网络)时肯定有注意到有个参数padding可以设置成 full , same, valid三种,不同参数的卷积形式略有不同。
-
full卷积
full卷积很像上述所提到的卷积, iamge(A)和kernel filter(B)卷积(A*B),就是把B翻转然后滑动累积和A的积分指。由于A是图片,这样就意味着要对A进行padding,卷积计算从B和A的最边缘有交集就开始计算,所以也叫 full convolution。full conv之后图片的大小会比 A图大。如下图所示(盗图,懒得画图了).
![]/images/conv/full.png) -
same 卷积
将图 A 和 B 进行 same 卷积,卷积之后 A 图的大小不变,所以就叫 same 卷积。s卷积计算的起始点是从 B 图的中心和 A 图有交集开始,same 卷积如下图所示,所以 same 卷积也会对 A 图进行padding。
![]/images/conv/same.png) -
valid 卷积
valid 卷积不需要对图 A 进行padding, 也就是大家平常看CNN 网络讲解图时常用的卷积形式,卷积计算从 B 被 A 完全交集开始计算, 如下图所示:
![]/images/conv/valid.png)
%emsp;关于 三种卷积对于输出map大小的影响,假设 输入 iamge 大小是 N*N ,kernel filter大小是 M*M,卷积时步长为s,如果padding的长度是p,则卷积之后map大小是 [ (N-M+2*p)/s +1 ] * [ (N-M+2*p)/s +1 ],这个公式可以套到下面三种卷积里面。
- valid 卷积,步长为1 时,输出大小 (N-M +1) * (N-M +1)
- same 卷积,步长为1 时, 输出map大小 N * N。pad的长度是 (M-1)/2, M 一般是奇数。
- full 卷积,步长为1 时, 输出map大小 (N+M-1) * (N+M-1)。pad的长度是 M-1
图像反卷积 ,deconvolution
其实关于图像的反卷积并不是真正意义上的反卷积,用反卷积命名是错误的,成为 转置卷积(transposed convolution )更为准确。反卷积可以让输出图比输入图大,CNN网络用反卷积通常是为了重构出原图的大小(经过conv之后图片一般会变小),这个在 full CNN 里面就用来重构出原图的大小,从而进行pixel 级别的语义分割。反卷积有两种形式,
-
上面提到的 full convolution 其实就是一种反卷积,如果步长为一,如下图所示,蓝色部分是原图 2*2, 白色部分是 padding的:

-
还有一种,并不是直接在原图四周padding,而是一种插入时的padding,如下,蓝色部分是原图 2*2, 白色部分是 padding的:

-
-
BWT算法
BWT(Burrows Wheeler Transform)
BWT,数据转换算法,其实也是一种压缩算法,基本思想就是找到字符串的重复部分来进行压缩,还可以用来进行序列比对。BWT会将字符串转换成一个类似的字符串,但是转换后的字符串的相同字符是相邻的,这样,我们就可以对数据进行压缩了。这个算法的解压缩也很方便简单。
BWT原理
BWT编码部分
BWT编码压缩步骤如下:
- 首先对要转换的字符串,添加一个不在字符串里的ASCII码表里最小的字符。如 AGGAGC ——> $AGGAGC,添加了 $ 。
- 对字符串进行依次循环移位,得到一系列的字符串,如果字符串长度为 n, 就可以得到n个字符串,如下面图里的第二列所示。
- 对2中的位移后的一系列的字符串按照ASCII进行排序,如下图的第四列所示,第三列是排序后的字符串的原index位置。
- 取位移后的一系列字符串的首字母出来作为 F 列, 最后一个字母作为 L 列。如下图 F 列 和L 列所示。
- L 列就是最后的编码结果。
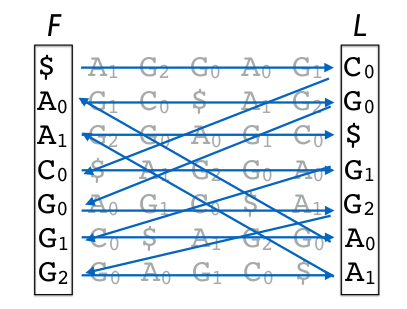
No. rotated index sorted F L LF 0 AGGAGC$ 6 $AGGAGC $ C C->$ 1 GGAGC$A 3 AGC$AGG A G G->A 2 GAGC$AG 0 AGGAGC$ A $ $->A 3 AGC$AGG 5 C$AGGAG C G G->C 4 GC$AGGA 2 GAGC$AG G G G->G 5 C$AGGAG 4 GC$AGGA G A A->G 6 $AGGAGC 1 GGAGC$A G A A->G 由编码过程,参考上图,其实可以发现BWT编码有三个特性(循环位移决定),
- L 列的第一个元素是源字符串的最后一个元素。
- 循环位移可知,同一行的 F 列和 L 列的元素在源字符串里是相邻的,而且 L 列元素的下一个字符就是 同行里 F 列的元素。
- 同一种字符在 F 列和 L 列里的rank是一样的,比方说, F 列里的第二个 A 和 L 列里的第二个 A 在源字符串里是同一个A。 F 列里的第一个 G 和 L 列里的第一个 G 在源字符串里是同一个G,rank如下图所示。
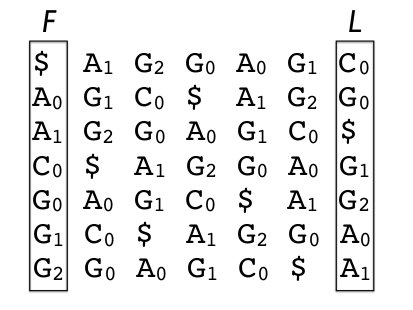
根据以上这三个条件, 我们就可以进行BWT解码,也就是解压缩。
BWT解码部分
BWT解码,已知 L 列, 推源字符串。
- 由 L 列 得到 F 列。因为L 列 和F 列其实都是源串的字符的不同排列方式,但是我们知道 F 列是按照 ASCII码排序的,所以从 L 就可以推出 F 。
- 根据第一个性质,我们可以得到源串的最后一个字符是 L 列的第一个字符,作为当前字符(下面依次往前递推)。
- 依据上一步得到的作为当前字符, 根据第三个性质,我们可以得到同一个字符在 F 列中的位置,作为当前字符。
- 依据 F 列里的当前字符,根据第二个性质,我们可以得到当前字符的上一个字符是同行里的 L 列里的元素,将新增字符作为当前字符,然后跳转到第 3 步。
- 直到所有字符全部推算出来。
整个过程如下图所示: