spp net 和 RCNN
在上一篇博客中,讲到了region CNN 可以用于目标检测和语义分割,但是,RCNN有两个很大的缺点:
- 计算量很大。 每张图片都要提取近2k张region proposal,而这zk张proposal其实有大量的重叠,而每个proposal都进行了卷积导致了大量的重复计算。
- RCNN的CNN网络只能接受固定大小的size输入(卷积层可以接收任意大小的输入,但是全连接层输入大小必须固定)。 region proposal的大小和长宽比是不一样的,RCNN为了解决这个问题,将所有region proposal 缩放成相同的大小,缩放过程中会导致图片扭曲变形
net希望加速网络,解决上述两个问题。对于问题一,spp net不再对所有的每张图片提取2k个region proposal进行卷积,而是每一张图片只卷积一次。对于问题二,spp net引入了spatial pyramid pooling layer,使网络可以接受任意大小的图片,输出却是固定的。
关于 spatial pyramid pooling layer,spp layer
spp,也叫spatial pyramid matching(SPM),其实是Bag of Words(BoW,词袋)的一种拓展,可以接受任意大小的输入,生成固定大小的输出。相比于BoW,spp可以维护图片的空间信息。这些spatial bins的数目是固定的,但是bins的大小则是正比于输入图片的大小,与之相反的是滑动窗口(slide windows)大小固定,数目则取决于输入图片的大小。
spp net中,比方说是vgg16的网络,用spp layer替换原来的最后一个池化层pool5。spp layer将卷积之后的features池化(pool)生成固定大小的features,然后将固定大小的features输入给全连接层或者分类器。过程如下图所示:
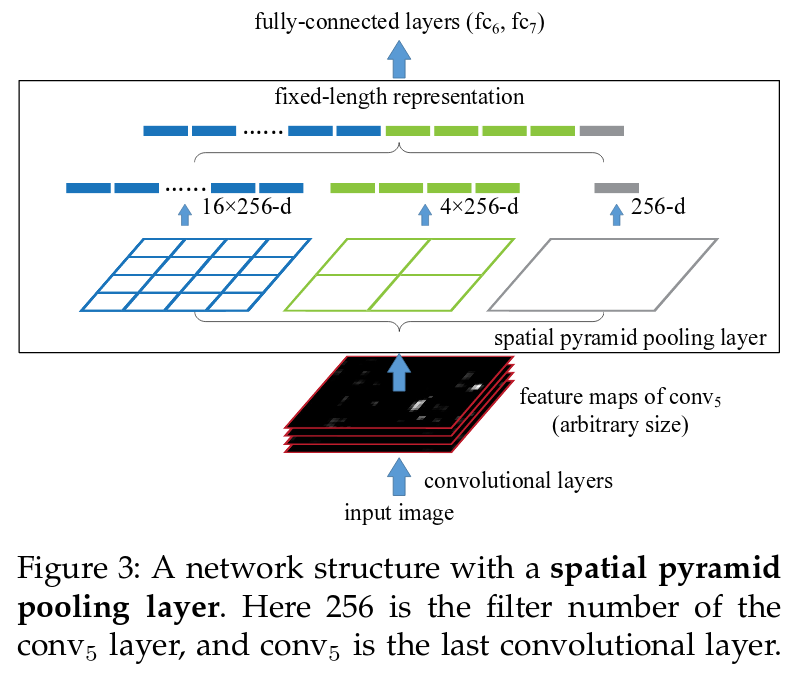
上图是3个level的bins,{4*4,2*2,1*1}。池化采用的max pooling,最后输出的维度是k*M,M表示bins的数目,k表示最后一个卷积层的filter数目。
关于spp layer 输入输出的大小计算:
假设 输入feature map(最后一个卷积层的map)的大小是 a*a, 一个pyramid level的bins数为 n*n,我们可以将这个pooling level 看成是sliding window pooling,而且这个window的size和stride值如下:
- window size,窗口大小为 ceil(a/n)
- strde, 移动步长为 floor(a/n)。
对于l个level的pyramid,就实现 l 个这样的 layer,将这 l 个输出拼接之后输入给全连接层。下图实例中就用了三个level,{3*3, 2*2, 1*1}, map size则是 13*13, 计算结果如下:

spp net 用于图片分类
论文里用Imagenet2012的1000类数据训练spp layer替换最后一个pooling layer的vgg16 网络。
- 数据预处理:先resize成256*256 ,然后随机crop 224*224, 水平翻转,改变颜色
- spp layer 之后是两个全连接层和 1000-way的softmwx 层,每个全连接层之后都要一个dropout layer
- 学习率初始值 0.01。
- 多个level pooling训练改善准确率。用了4个level pyramid {6*6,3*3,2*2,1*1}
- 多个size训练提升准确率。traing size有224和180.
spp net + svm 用于目标检测
- RCNN网络对每个region proposal都进行卷积通过预训练好的CNN网络提取feature vection。
- spp net则用预训练好的CNN网络对每张图片只提取一次 feature map,然后将proposal在图片上的位置映射到feature map上来提取相应的区域的feature map,然后对proposal 的feature map用spatial pyramid pooling 得到固定长度的 feature vector。
然后固定长度的特征向量输入全连接层, 最后和RCNN一样,每个类别训练一个SVM进行分类,其实懒的话也可以直接在全连接层后面加上softmax layer 分类。接下来的目标定位也和RCNN里面一样。
这样来看对每张图片,不需要进行2000次卷积,只需要进行2000次映射,spatial pyramid pooling,最后通过全连接层,即可得到固定长度的特征向量。
预训练好的CNN网络可以直接是ImageNet预训练的网络,也可以进行fine-tuning,将最后的softmax层改成21路的输出,fine tuning时只调整全链接层的参数。
目标检测也可以用多个size的图片进行训练。把输入图片的尺度增加,把原图resize成短边为s ={480,576,688,864,1200}的大小来分别计算 feature map。这样就有多个不同大小的feature map,但对于每个region proposal,只从这些feature map中选取一个映射之后大小接近于 224*224的进行sp pool。