1. AM算法: activation maximizing
AM:节点最大化,通过最大化某个隐藏层节点单元来探究该节点所学习到的 input pattern。简单的做法就是,对于给定某个隐藏层节点,找到一个 input sample 能够最大化的激励这个节点的值。这是一个优化问题,对于一个深度网络,网络参数为 θ。假设 θ 是已经训练好了的网络的参数值,是固定值;x 则表示输入样本,hij(θ,X)表示第 j 层、第 i 个节点单元的激励值,那么hij就是关于 θ 和 x 的函数,θ 已知。那我们就可以通过下面这个公式来计算输入 x,x既是对于该节点所学习到的特征的可视化结果。
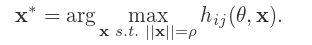
该问题是一个非凸优化问题,我们可以通过 gradient ascent 找到局部最优解。类似于知道input x 时优化 θ 的过程。先随机一个 输入 x值,计算 hij 的值,然后求hij对于 x 的倒数,利用gradient ascent算法对x 进行更新直至收敛。一个手写体识别的AM可视化的例子如下:

上图中,第一行的三列分别是用AM对DBN网络的 1st layer、2nd layer、3rdlayer的36个节点单元的可视化结果。
然后 第二行的三列分别是用AM对SDAE网络的 1st layer、2nd layer、3rdlayer的36个节点单元的可视化结果。
2. inverting representations
inverting representations, 这个方法和AM算法有着异曲同工之妙,对于一个已经训练好的参数固定的网络,假设某个隐藏层的表达representation函数为 Φ,则Φ是θ和输入X的函数。给定网络参数θ和待逆推的表达 Φ0=Φ(x0),来计算一个输入image sample,使这个输入图片 x 所生成的表达和给定的表达 Φ 尽量相似。最小化下面这个公式:
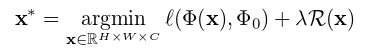
通过最小化这个式子,就可以使输入图片 X 和 原图片 X0 在那个给定的高维表达上尽量的相接近。
上式中,loss 函数l是比较输入图片生成的表达 Φ(X) 和给定的表达 Φ(X0).loss的计算方式如下:
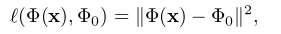
后面的 R(x) 是正则化项, λ是超参。
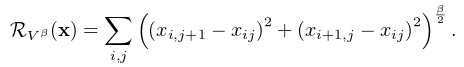
关于计算 x 的方式,和AM算法类似,也是优化问题,最小化 loss ,对 x 求导,利用 grident ascent 对 x 进行更新直至收敛。
code inversion 可以用来重构输入图片,也有论文,为了合成风格迁移的图片,利用code inversion 算法来同时重构目标图片的整体布局和风格图片的纹理信息来合成风格迁移图片。
3. MFV: Multifacet fearure visualization
AM 算法和 code inversion 的初始输入input sample 是一个随机值。但是由于满足的条件的输入图片非常的多,可能会生成无法识别的图片。原来的AM算法还有以下的几个问题:
- 图片颜色分布不自然
- 识别出来的图片片段大量重复
- 高维节点单元其实是可以学习多个方面(facet)的信息的,如在面部检测单元可以同时检测到人脸和狮子的脸,但是简单的AM算法是无法同时可视化出这些 facet。
为了解决多facet的问题,就有论文提出的MFV算法就可以可视化出节点检测到的多个facet的信息。
该算法利用了AM 算法作为基础,大概步骤如下,首先我们假设该节点检测到的是类别 A,然后我们从数据集中把所有类别A的图片取出来作为新的数据集 U。
输入: 数据集 U,和 facet 的数目 k
- 对U中的每张图片计算指定隐藏层的高维表达 φi,例如指定fc7 layer 。
- 利用PCA 将 Φi 从 4096维降到50维。
- 用 t-SNE把整个 θ降到二维 2d embedding来进行可视化。
- 通过k-means聚类将 2d embendding的所有图片聚类成 k 个类别。
- 对于每一个类别,执行下面步骤得到 k 个 facets 的可视化 {X1,X2,…Xk}。
- 选取离质心最近的m=15张图片来计算得到一张 mean image X0,
- 初始化输入为 X0, 运行 AM算法。
因此,可以发现 MVF 可以获得 K 个输入样本,每个样本代表一个facet。如下图:

图a,可以获得节点检测到的电影院室内室外或者白天晚上多个facet的可视化结果。
图b,可以获得车子的不同颜色和不同角度(车前车后)多个facet的可视化。
对于AM算法可视化结果有片段重复现象,利用 center-biased regularization可以改善这个现象,具体做法就是先生成一个模糊的中心对象,然后微调目标的中心像素点来生成清新的中心固定的对象,如下图所示:

参考论文:
- Understanding Representations Learned in Deep Architectures
- Understanding Deep Image Representations by Inverting Them
- Multifaceted Feature Visualization: Uncovering the Different Types of Features Learned By Each Neuron in Deep Neural Networks