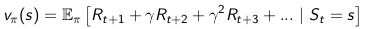最近在看reinforcement learning 的视频课程,记录了一些笔记,顺便整理成博客,课程内容复杂有些难理解,博客也许会有些错误的地方,望指正谅解,大家一起学习.
机器学习分类
机器学习大概可以分为以下几个类别:
- 监督学习:从有标注的训练集中训练学习模型,可以对新数据进行预测。eg. 决策树,回归分析等
- 无监督学习:和有监督相比,训练集没有标注,eg 各种聚类算法。
- 半监督学习: 介于以上的两者之间。
- 强化学习:基于环境而行动,以获得最大化的预期利益。
强化学习课程官网,主讲人是David Silver。
课程视频油管上可以找到,不能翻墙的小伙伴可以点这个强化学习百度网盘。
强化学习
强化学习: 是指一个智能体(agent)从环境(environment)中学习从状态(state)到动作(action)的映射。是一种无监督学习,没有label,而是反馈信号,而且反馈具有延时性,并不是即时的。比方说下棋,这一步所下的棋所产生的影响并不会完全的即时反馈出来,在未来的步骤中也会有所影响。强化学习组成如下:
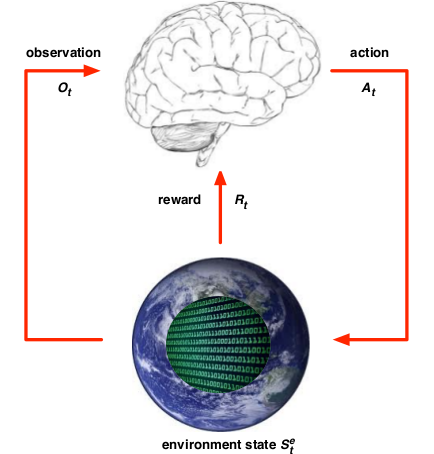
- agent,智能体(上图中的大脑)
- environment,环境(上图中的地球)
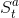 :agent的状态(state),表示agent自己内部的表现,这是强化学习学习时所用到的信息。
:agent的状态(state),表示agent自己内部的表现,这是强化学习学习时所用到的信息。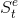 :environment的状态,这是环境自己的状态,一般对agent不可见
:environment的状态,这是环境自己的状态,一般对agent不可见- At: 动作(action),表示 agent在某状态 S 采取的动作
- Rt; 回报函数(Reward),在 S 状态, 采取 A 动作所获得的奖励。
- Ot: 观测值(observation)。
整个过程: 在某时刻 t :
- agent行为:
- 执行动作 At
- 接收Observation Ot
- 接受reward Rt
- environment:
- 接收动作 At
- 发射Observation O(t+1)
- 发射reward R(t+1)
- 进入下一时刻 t+1 ,重复1,2,3步骤。
对于整个过程下来, 最后就会得到一个observation,action,reward组成的序列 Ht= O1,R1,A1,…At-1,Ot,Rt.
环境分为两种:
-
fully observable Environment:这种就是agent能够直接观测到环境的状态,agent state = environment state = observation :
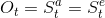
这种情况下,就是一个马尔科夫决策过程(Markov decision process, MDP)。 -
partial observable Environment:agent不能直接观测到环境的状态,所以agent 和environment的状态不同。
策略,policy
policy,是一个智能体的行为,是从 state 到 action 的映射,表示在某状态下采取的动作的概率分布。
a = π(s)
值函数, value function
value function,是对未来reward的预测,用来评估当前状态的好坏。