Welcome to CJW's Blog!
关于deeplearning, 关于 machine learning-
deelearning
deeplearning相关算法
- logistic, 逻辑回归 make LogisticModel
-
mlp,
make MLPModel -
AutoEncoder
-
DeepAutoEncoder,
make DeepAutoEncodelModel -
RBM
make RBMModel -
DBN(LayerWiseRBMs预训练, mlp finetune )
make DBMModel - activitionMaximization ,在RBM和LayerWiseRBMs 中, 用于可视化隐藏层所学习到的feature
- MultiModalModel, 多态模型,可以处理多种数据输入
make MultiModalModel
-
AdaBoost 算法
提升方法,AdaBoost 算法背景
AdaBoost算法, 是一种经典的提升算法。提升算法基于一个很简单的想法,三个臭皮匠抵个诸葛亮。要解决一个复杂的问题,多个专家的判断的综合结果要比任何一个单一的专家的判断好。
首先介绍两个概念,强可学习,弱可学习。强可学习: 一个概念,如果存在一个多项式学习的算法能够学习他,并且准确率很高,则认为这个概念是强可学习的。弱可学习: 一个概念,如果存在一个多项式学习算法可以学习它,但准确率只是比随机猜测略好,则这个概念就是弱可学习。从这里看,强可学习和弱可学习似乎差别很大,学习到的准确率天差地别,然而其实,两者有相通之处。后来有人证明了一个很有趣的事实:一个概念是强可学习的充要条件就是这个概念是弱可学习的。
对一个复杂问题,虽然一次性找到一个准确率很高的学习算法是一件很困难的事情,不过找一个弱可学习的算法并不难。由于上面提到的强可学习和弱可学习等价性,就可以想到,先找到弱可学习算法, 然后将它提升为强可学习算法,这也就是提升算法。简而言之,假设对于分类问题,给定一个训练样本集,利用弱学习算法,反复学习得到一系列的弱分类器,然后组合这些弱分类器得到一个强分类器。大多数的提升算法,使用不同的训练数据分布调用弱学习算法来学习这一系列的分类器,也就是说不同的分类器,训练数据的分布不同。
由上面可知,提升算法面临两个问题:一是如何在每一轮的弱分类器的学习中改变训练数据的概率分布;二是如何将弱分类器组合成强分类器。问题一, AdaBoost算法的做法是提高上一轮弱分类器错误分类样本的权值,降低正确分类样本的权值,这样上一轮错误分类的数据在这一轮分类器学习中会得到重视。问题二,AdaBoost采用加权多数表决的方法,即分类准确率高的弱分类器权值高,反之权值小。AdaBoost 算法步骤
AdaBoost算法:
** 输入: **
二分类训练数据集,T = {(x1,y1), (x2,y2), …,(xN,yN) },共 N 个数据对。
弱学习算法,M 个基本分类器 G1, G2,… ,GM
** 学习参数: **
训练数据的权值分布,D1,D2…DM。第m个分类器的数据权值分布: Dm = (w11,w12, … w1i, …,w1m)
弱分类器的权值,也是 M 个。α ,1~M个。
** 输出: **
最终的强分类器 G(x)。算法步骤:
- 初始化第一个弱分类器的的训练数据权值分布:

这里假设的训练数据是均匀的权值分布,来学习第一个分类器。 - 依序训练 1~M个弱分类器,每个分类器都顺序执行下面几个步骤:
- 对第m个分类器,使用权值分布为Dm的训练数据集学习,得到基本分类器Gm:

不同的权重分布,对于不同的决策函数,都对应着最佳的分类决策,即 em 最小。 - 计算Gm(x)在训练集数据上的分类误差率:

Wmi表示第m轮的第i个实例的权值,由式子可以知道Gm(x)在加权训练数据集上的分类误差率是被Gm(x)误分类的样本的权值之和。 - 计算Gm(x)的加权系数:

这里的对数是指自然对数.由公式也可以发现,分类误差率越小的,基本分类器的权值越大,而且当em<=1/2时,α 才大于0。所以分类误差率越小的分类器在最终的分类器中的作用越大。 - 更新训练数据集的权值分布:


更新的训练数据权重值为下一轮的分类器学习做准备,其中,Zm是规范化因子:

- 对第m个分类器,使用权值分布为Dm的训练数据集学习,得到基本分类器Gm:
- 构建最终的分类器,强分类器:

其中f(x)是基本分类器的加权线性组合, sign是sigmoid非线性变换。
值得注意的是,分别对与每个m,wim,i=1~N,之和是1 ,但是所有的 αm(m=1~M) 之和不为1。
训练误差分析
AdaBoost最基本的性质是算法能在学习过程中不断减少训练误差,即在训练数据集上的误差。
- 初始化第一个弱分类器的的训练数据权值分布:
-
region cnn目标检测,语义分割
简要介绍
论文笔记:
Region-based Convolutional Networks for Accurate Object Detection and Segmentation。Ross Girshick大神后来基于此篇又研究发表了很多论文, 提出了SPP net 和fast RNN。论文里提出用CNN网络来进行目标检测, 不同于图片分类, 目标检测需要在图片内对目标进行定位。这面临着两个问题,一是如何用deep network 定位,二是,如何用现有的少量数据训练一个更泛化的模型。
对于第一个问题,有一种办法是将检测问题转换成回归问题,但这样检测多个目标时需要很复杂的解决办法或者特定假设每张图片里目标的数量。另一种方法是采用滑动窗口,但这样就需要所有的目标有共同的长宽比。 论文里最后采用的recognition using regions方式进行定位,这个方法已经被成功的运用在目标检测和语义分割上。rcnn的步骤主要是三步:- 每张图片提取大约2000张的类别独立的 region proposal。
- 采用CNN 从每个region proposal进行固定长度的特征提取。
- 用SVM 进行分类,不同类别分布训练一个SVM。
另外,对于数据稀缺问题,可以采用有监督预训练的办法解决。先用大数据例如ILSVRC预训练, 再用domain-specific的数据进行fine-tuning(这个方法也叫迁移学习,transfer learning)。
R-CNN 基本策略
网络的基本流程如下图所示:
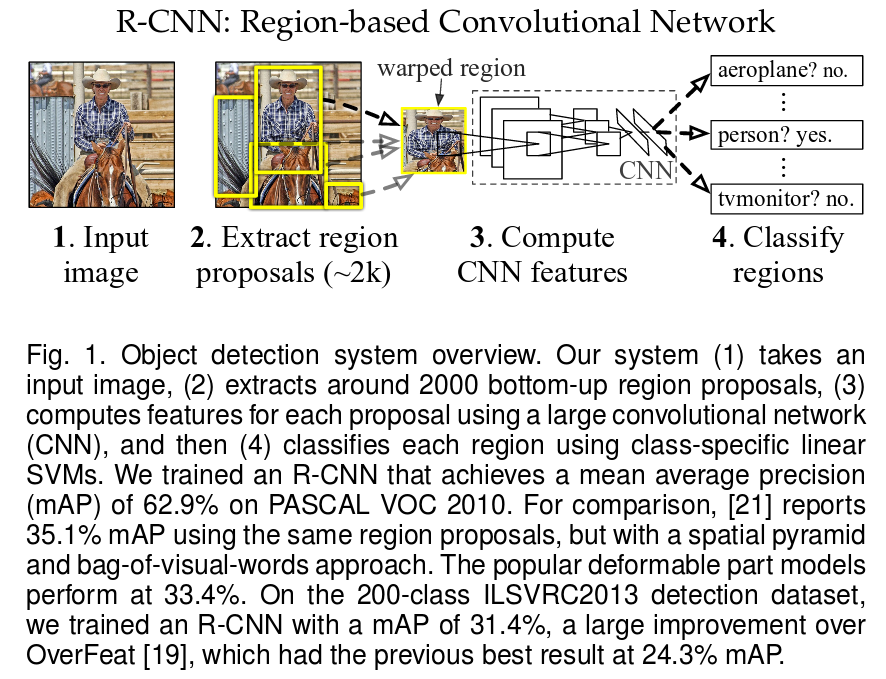
1. region proposal,候选框提取
每张图片要生成大约2000张regionproposals。对于生成类别独立的region proposal,有很多方法,例如:objectness, selective search, category-independent object proposals 以及Ciresan等。论文里采用的是selective search。
2. feature extraction,特征提取
这一步是用一个CNN网络从region proposal中提取一个固定长度的特征向量。特征向量维度是4096维。CNN网络只接受固定大小的输入如227*227,由于候选框的大小和长宽比不一定,所以首先要将不同大小的
region proposalwrap成固定大小的。转换方法很多,论文里采用的最简单的方法,如下图:
CNN网络训练提取特征:
训练CNN网络提取region proposal的特征向量,CNN的训练分为两步:
-
supervised pretrain 用 ILSVRC2012 classification的数据预训练 CNN 网络,该数据是一个 1000-way的分类
-
domain-specific fine-tuning 对预训练好了的网络,用wraped 之后的proposals 进行训练。不过如果这个domain数据是N个类,所有CNN网络的最后一层要从1000-way替换成 N+1 way的layer(该layer的参数初始值随机),里面有一个是background。IoU overlap是指两图片重叠面积和相并面积之比。论文里面,设置如果proposal和ground truth 的 IoU overlap >= 0.5时,则认为这个proposal是positive(正样本)的,其余的negative(负样本)。
3. object category cassifier,分类器
每一个类分别训练一个二值SVM分类器,将用CNN网络提取到的那些proposal的特征向量作为svm的输入,得到SVM对于这些proposal的评分结果,对于一张图片的score之后的region proposal,采用非极大值抑制技术找出最终的候选框。
在正负样本的设置中,与fine-tuning 里不同。background为负样本,IoU overlap 阈值<=0.3的也是负样本;只有ground truth是正样本, IoU在0.3到1之间的region忽略。论文发现如果fine tuning时也使用SVM训练时正负样本的定义,准确率下降很多,作者猜测是因为IoU在0.5到1之间的样本被忽略的话,训练数据会少很多,而fine tuning需要一个比较大的数据,可以避免过拟合。但是这些忽略的样本用到SVM训练中的话,会降低定位的精准度。$emsp;还有一点值得说的是,论文里还提到,对SVM分类之后的region proposal 使用bounding box regression可以减少定位误差,论文里的数据提升了3-4个mAP的百分点。
-
Batch Normalization的理解与分析
Batch Normalization(BN算法)
BN算法是论文
Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift提出的算法,算法看起来很简单,可以当作一个单独的层次加入到网络中,效果非常显著啊。背景
在深度网络的训练过程中,整个网络的输入数据我们一开始就会进行归一化处理,但由于前面网络的参数微小变化,会随着层次前向逐步累积放大,会使后面层次的网络的输入的分布改变,这就是Internal covariate shift ,这种情况下就需要我们有较好的权重初始值和降低学习率,从而导致学习较慢。
然而,如果每一层的输入数据都有固定的分布(包括训练数据和测试数据),会对训练比较有利,模型也会有较好的泛化能力。于是,大家就考虑到对每一层的输入进行归一化处理来固定分布,Batch Normalization就是解决了这个问题(减少Internal covariate shift)。意义
BN算法很厉害,深度网络训练时参数初始化很重要,各种超参(学习率、正则化系数、权重衰减系数等)和trick的选择也很让人很麻烦,BN算法就可以帮我们省却这些麻烦。
- 可以选择较大的学习率。在有BN算法的模型中,可以一开始就选较大的学习律而不用担心gradient vanish,也就不需要逐个尝试学习率大小选择最合适的。
- 权重初始化可以相对随意些。BN减少了gradient flow 对权重初始值的依赖。
- 去掉Dropout。BN算法可以达到dropout的目标,因此可以去掉Dropout而不产生过拟合。
- 去掉L2正则化。BN模型中,权重的L2 loss会减少5倍。
- 加速学习率的衰减。通常训练时,学习率会以指数形式衰减,在BN模型中,衰减速度可以加速6倍左右。
- 可以把数据彻底打乱。避免某个样本总是被batch选中,可以提高准确率1% ?
- 减少photometric distoritions(不懂这是个啥)。
- 加速训练过程。以更少的training steps可以达到相同的准确率。
Normalization 和Batch Normalization
众所周知的是,如果神经网络的每一层的输入都是白化数据(例如线性变换成0均值,1方差,feature去相关的数据)的话,网络训练时收敛更快。但是如果完全白化所有层的输入,代价太大。在讲BN之前,我们先来看一下一个简单的归一化处理操作,可以将数据近似白化处理,也就是0均值,1方差,但是feature之间相关。
1. 近似白化处理
就是下面的这个公式,简单粗暴,大家肯定在其他地方的都用过,对每一个神经元进行归一化处理,就是简单的将数据变成0均值,1方差:
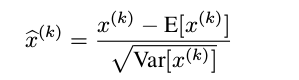
但是,其实简单的归一化处理,效果并不好,它会改变前面这一层的所学习的特征的表达。比方说,有一个sigmoid曲线分布的输入,如果进行简单的归一化,原本分布在非线性区域(s曲线两端)的就被强制归一化到线性区域(s曲线中间)。想要解决这个问题,归一化处理必须是一个恒等的变换,特征表达不能改变,由此,就产生了BN算法。
2. BN算法
为了保证恒等变换,BN算法在上面的归一化处理上加入了非常重要的一步,新引入了两个可以学习的参数,对归一化之后的数据进行下面的重构处理:
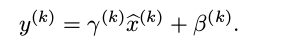
其中,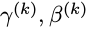 是可以学习更新的参数,每一个神经元一对这样的参数。可以发现,BN算法可以当成一层网络加入到神经网络模型中,就和全链接层,激励层,卷积层,池化层等一样的。该层有两个可学习参数。而且当有:
是可以学习更新的参数,每一个神经元一对这样的参数。可以发现,BN算法可以当成一层网络加入到神经网络模型中,就和全链接层,激励层,卷积层,池化层等一样的。该层有两个可学习参数。而且当有:
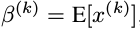
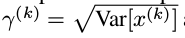
该BN层可以恢复该层的输入层所学习到的特征表达。在训练过程中,两个参数不断更新学习,这样就可以恢复原始网络所学习的特征分布。BN网络
首先写一下BN算法的前向推导:

理论上,网络训练是在整个数据集上,归一化时,应该用整个数据集来计算均值方差进行归一化,但在SGD优化算法中,这样并不是一个可行的办法。退而求其次,论文里提出用mini-batch里面的数据来估计均值和方差。1. BN网络
在全链接网络中,BN层通常在全链接层之后,激励层之前(激励层:sigmoid,tanh,ReLU等)。例如,本来全链接网络的forward如下所示:
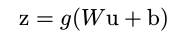
在加入BN层之后:
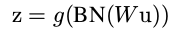
不过上面这个式子里的偏置参数 b 其实可以去掉,因为 b 会被均值归一化,重构时也有偏置函数。2. CNN网络中的BN
CNN 中的BN层也是在卷积层之后,在激励层之前。不过有点不同,全链接网络当中,均值化是对每一个神经元进行均值化,但是如果CNN网络也对每一个神经元均值化,这样会产生非常多的
参数对。比方说,如果某一层,有64个feature map,每一个map大小是60**60,如果每一个神经元都归一化,那么就会有64*60 *60个参数对,这违背了CNN权值共享的精髓思想。考虑到权值共享,作者提出对整个feature map进行整体的归一化,把一个feature map当作一个神经元,这样就只有 64 对参数了。
-
deeplearning 反向传播的数学推导
很多人对神经网络的前向过程比较清楚,对反向传播算法则比较模糊。因此想在这里简单的写一下反向传播过程中权重更新的推导过程。反向推导主要就是一个对权重值求导的过程, 求导时利用了链式法则。这里简单的介绍一下全连接的神经网络的反向传播的推导,RBM, autoencoder, deepAutoEncoder和 RNN 的推导与这种全连接的反向求导推导类似,CNN网络的则要不一样些,但其实也还是利用的链式求导法则。
神经网络的一个训练过程,可以看作是优化权重来优化代价函数的过程。多层神经网络的参数优化问题其实是一个高阶的非凸优化的问题,普通的优化算法很容易陷入较差的局部最优解。神经网络大多采用随机梯度下降算法,可以获得一个较好的局部最优解,(pre-trainging 可以获得一个较好的接近局部最优解的出世迭代点)。代价函数可以采用交叉熵代价函数、平方损失函数等,这里推导采用交叉熵的代价函数。logistic 求导
先介绍以下logistic模型的求导过程,这是一个单层的神经网络,多层的神经网络的求导其实和这个一样,只是一直往前递推。
FeedForward,前向传播过程
下面三个式子就是Logistic的前向传播过程, 其中 E 表示的就是代价函数
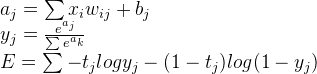
上式中,a表示全链接结果,a到y的计算是softmax函数,最后 E 则是代价函数的计算方法。softmax的输出被归一化到0-1之间,所有值相加是1,可以认为是预测结果的概率值BackPropagate,反向传播
反向传播过程是计算权重w,b的梯度,也就是代价函数E对参数的偏导值。
根据链式求导法则一步步往前求导,过程如下所示:
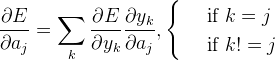
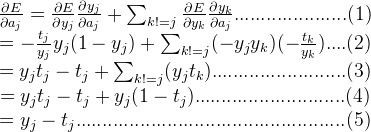
最后,再求w,b的偏导就是:
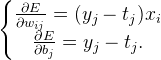
求出偏导值后,用权重参数减去其对应的梯度,就是更新之后的权重参数:
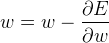
MLP 求导
MLP其实就是一个多层的全连接网络,基于上面的logistic的反向过程,我们可以用同样的方法来推导MLP的反向传播过程。
FeedForward, 前向传播过程
下面是一个两层全连接,一层sotfmax连接网络的前向传播过程,其他层次数的MLP类似:
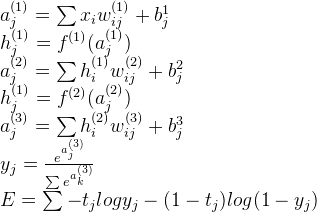
其中f()表示激励函数,可以是sigmoid,tanh,ReLU等函数Backpropagate, 反向传播
我们首先假设 E 对第 l 层的 a 的偏导值如下:
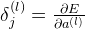
由上面的logistic的推导过程,我们可以得到MLP的最后一个softmax层的推导如下:
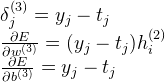
由上式,我们继续往后推导求第 l 层的 a 的偏导值:
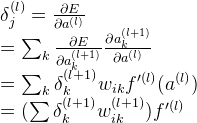
则第 l 层的w,b的偏导值如下:
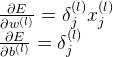
利用链式求导法则,一直往后推导,就可以计算得到第一层的权重参数的偏导值,最后,反向推导过程完成。
-
RBM训练的实用指南
RBM训练的实用指南
这是很久以前,最初学用RBM时候看的Hinton大牛的论文,A Pratical Guide to Training Restricated Boltzmann Machines。趁现在有时间整理一下, 里面讲述了RBM训练过程中各种实用有效的训练tricks。
1. RBM简介
这篇博客不打算具体介绍RBM的结构和推导算法,偏向于介绍训练tricks,所以这一块只会作一些简单的介绍。RBMs经常是被当作生成模型在使用,最重要的一个作用是作为DBN网络的组成部分。RBMs采用CD算法(constrastive divergence)或者PCD(persistent constrastive divergence)算法训练。
在网络构建和网络学习的过程中,有很多的参数都是需要大量的经验来进行抉择, 比方说权重值的初始值、隐藏层单元的数目、学习率的大小、batch size的大小以及动量的大小等等。算法方面还需要选择是二值单元还是高斯单元,网络参数更新采用什么样的算法,SGD还是Adadelta等。还有该如何监控训练过程并相应的调整参数。 以下这些tricks,不只是RBM, 也会相应的实用于其他神经网络中。2. 调参技巧
- batch size的大小
样本可以一个一个的训练,也可以批量的一个batch一个batch的训练,这个batch的size一般是10——100。batch式的训练可以提升训练速度,网络可以使用矩阵相乘,充分利用GPU的优势。为了避免学习率(lr)受batchsize的影响,一个batch计算出来的梯度最后会除以batchsize。 如果batchsize太小,网络训练会比较慢,但如果太大,在使用SGD训练时,每一个梯度估计的权重参数的更新会变小。理想的batchsize的大小一般是数据类别class的大小。每一个batch里,每个类包含一个样本,这样可以减少从整体选取单个batch时的取样误差
- 学习率 lr的大小
如果 lr 太大,会导致步长增大,梯度下降无法到达(局部)最优,算法上看是重建误差显著增加,最终导致权重参数(weight)可能explode。但如果 lr 过小, 由于小噪声的影响, 会导致训练周期过长。在网络训练的后期,可以适当的降低学习律。训练时可以先设置lr为0.01,观察cost下降情况,来适当的调整,如果cost在下降,可以逐步的增大lr, 如果cost在增加,则需要减少lr。
- momentum
momentum在SGD算法中可以有效的増加学习速度,一般大小设为0.9左右。这个相当于是加入了惯性的思想
其中m既是指momentum,v 是速度- 2.4 weight-decay
weight decay是指对较大的权重参数值加以惩罚措施, 具体上是指在gradient上就加入一个多余项。最简单的惩罚措施是L2正则化,可以有效的避免过拟合,下面是L2正则化:
其中 η 是指学习率 lr, λ则是L2参数, λ的大小一般在0.01——0.00001之间。
3. 监控过拟合
每隔几个epoch则计算一次train data 和 valid data的cost, 并比较,如果valid的cost开始比train的越来越大,则说明模型开始过拟合。过拟合一般情况,train data的错误率越来越低,而valid的责减少缓慢甚至开始不减返増。
4. 网络节点单元类型
大多数情况下,节点单元是二值的,但也可是高斯单元,即实值单元。ps,过去大多数网络的参数的权重都是实值的,现在有人开始研究二值权重的网络。